
Published August 20, 2019 by Ben Willingham
Tags: GPU
Testing V-Ray GPU Rendering with NVIDIA NVLink
As GPU technology has advanced over the years, GPU rendering has become more advanced and popular due to its speed advantage over CPUs in visual rendering. In addition, a GPU rendering workstation is much more flexible and scalable than a CPU workstation, with many being able to fit two, four, or even eight GPUs. The main drawback to GPU rendering is the limited VRAM for each GPU. In the past, even the top GPUs had only 24 or 32GB of VRAM, compared to CPU rendering workstations that could easily pack 128GB or more of RAM.
However, with last year’s launch of the RTX GPUs and the introduction of NVLink to the Quadro, Titan, and GeForce lines, it is possible to have nearly 96 GB of VRAM available for rendering when using two Quadro RTX 8000s due to the memory pooling capabilities of NVLink. Even if you don’t need a full 96 GB of VRAM, NVLink has now made it extremely affordable to get 22 GB of VRAM with two RTX 2080 Tis — at a third of the price of the past generation 24 GB option and offering over twice the performance. With these recent advancements, GPU rendering is becoming a more and more viable solution, retaining its speed advantage over CPU rendering while increasing the capacity for complex professional renders.
To better understand the functionality of NVLink in V-Ray, we tested four of the top NVIDIA GPUs in the APEXX Enigma S3, a BOXX workstation designed specifically for dual-card GPU rendering. This Enigma S3 is powered by an overclocked Intel i9-9900k, a perfect combination of clock speed and thread count excellent for driving GPU rendering and viewport manipulation that can also be used for hybrid rendering if you want an extra speed boost.

To ensure that the I/O and memory of the system were not causing any bottlenecks, each configuration was tested with 64GB of Samsung DDR4 at 2666 MHz and a Samsung 970 Pro 512 GB NVMe SSD.
Because the 9th Gen Intel processors used in this workstation only have 16 PCIe lanes to communicate with PCIe devices, normally if you were to use two GPUs the 16 lanes would be split into two 8x connections for each of the GPUs. However, the Enigma S3 is designed for multi-GPU setups so the motherboard includes a PCIe switch that can provide each of the GPUs with up to the full 16 PCIe lanes to communicate with the CPU. Alternatively, if you want to add a less powerful third graphics card to edit scenes in the viewport and run your monitors while you use the other two GPUs for rendering, the PCIe switch will keep the rendering GPUs at 16x and 8x. Meanwhile, the viewport GPU can be at 8x, compared to a non-PCIe switch setup where the cards would be at 8x/4x/4x.

In our first test, we ran the V-Ray Next 4.10.05 GPU benchmark on both the single and dual card setups to get a good idea of both the scaling and relative speed of the cards. In the tests, we ran only the GPU segment of the test using one or two GPUs (not hybrid rendering with the i9-9900k). It is also important to note that for this test, NVLink was off.

For a more memory-intensive render, Chaos Group provided us with the City GPU scene in Autodesk 3ds Max. When rendering the scene at 4K on a single card, we saw 29GB of VRAM usage, meaning that the 2080 Ti, Titan RTX, and RTX 6000 were unable to render the scene without NVLink. However, once the NVLink bridge was installed and activated, the Titan RTX and RTX 6000 graphics cards could complete the render as well as the RTX 8000 GPU.
Moving to NVLink, we did see around a 12% performance loss, but this still puts the GPUs far ahead of their CPU competitors and is well worth the nearly doubled VRAM. In addition, if NVLink is not needed (for example, for the RTX 8000 in this scene), it can be easily toggled in the NVIDIA Control Panel by selecting either “Maximize 3D performance” or “Disable SLI” in the SLI Configuration tab.
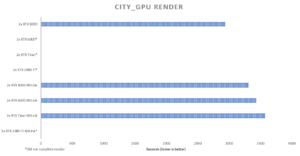
The NVIDIA Quadro RTX 8000, Quadro RTX 6000, and Titan RTX are also very close in the City GPU benchmark although the Quadros do come out slightly ahead of the Titan both with and without NVLink. This could be because of the dual fan design of the Titan cooler, which is less optimal for multi-GPU setups compared to the blower style Quadros, or the marginally slower base clock speed (although the boost clock speed is consistent for all three). In addition, the larger memory size of the RTX 8000 likely allows V-Ray to use more memory which can be more optimal for speed.
For dual card rendering in the Enigma S3, I recommend the NVIDIA GeForce RTX 2080 Ti, the Titan RTX, or the Quadro RTX 8000, based on how much VRAM you require. If you need an even faster four or eight GPU setup like the BOXX APEXX S4, APEXX X4, APEXX T4, APEXX W8R, or APEXX D8R, I would advise going with the Quadro RTX 6000 GPUs instead of the Titan RTX GPUs for a configuration that has around 48GB of VRAM. Unfortunately, while all the other cards mentioned may be purchased with blower coolers for multi-GPU setups, only the Titan comes with the Founders Edition dual-fan cooler that overheats when placed adjacent to other cards.
Looking to the future, GPU rendering is extremely promising. The new NVIDIA Turing RTX graphics cards already save valuable time over the previous Pascal generation, and this is before the new RT cores are utilized by V-Ray (although their Tensor Cores are used in the NVIDIA OptiX AI Denoiser implemented in V-Ray Next). According to Chaos Group, there is an internal build of V-Ray GPU in the works that offers a speed boost of 47-78% for RTX cards, with more performance gains expected in the coming months of development. 1 In fact, according to preliminary testing done by Chaos Group, the 2080 Ti with RT core support will more than double the performance of the 1080 Ti. Additionally, Chaos Group’s work on out-of-core geometry for the GPU engine will further reduce VRAM usage, making GPU rendering both more accessible and more efficient for geometrically complex scenes. As GPU and GPU rendering technology progresses, I expect GPU rendering will become even more widespread and eventually take over as the main production render in most workflows.
1 https://www.chaosgroup.com/blog/profiling-the-nvidia-rtx-cards#